

Overfitting In Academia
Overfitting In Academia
Can Mathematical Solutions Help Scientific Stagnation?

Overfitting is a problem in mathematical modeling where a model fits a set of data essentially by ‘memorizing’ each point, rather than by attempting to discern general trends in a relationship.
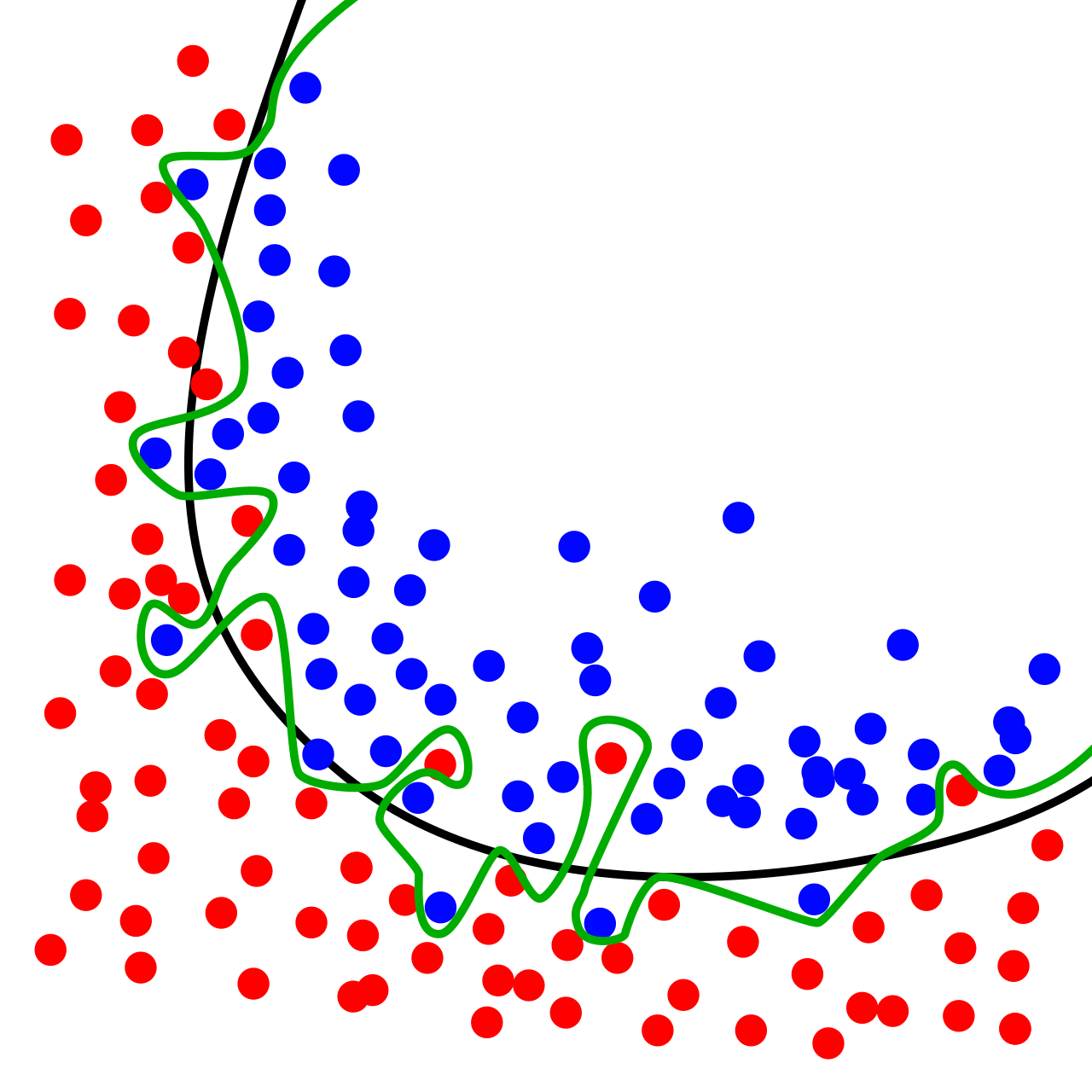
Although an overfitted model often perfectly predicts the data on a training set, it has much worse out of sample predictions. This problem arises because the method of model selection is not the same as what we actually want the model to do. In the above picture, a model is selected for minimizing the number of dots incorrectly categorized as red or blue in the training set. The green line is much better at this than the black line; it doesn’t get any wrong. But we already knew the colors in the training set. What we actually want is a model that can predict the color of dots that no one has seen yet. The green line is terrible at this but the black line does a pretty good job.
In Academia
Academia has an overfitting problem. Candidates are rigorously tested for decades on training tasks like GPA, Ivy League admission, reproduction of existing research, internships with field leaders, and citations for extending current paradigms.
But our selection criteria do not match with what we want academics to do. The out of sample prediction ability of academics is worse than random and laymen. They know lots about research they’ve already been tested on, but are rarely better than random at guessing the results of experiments in their field that they haven’t seen before. Citations and academic rank do not increase the ability of economists to predict the outcome of economic experiments or political events.
Out of sample tasks for Harvard graduates
Prediction and general knowledge is not all we want from academics, however. We also want them to produce advances in science and technology. Here too there is misalignment between our selection criteria and desired output.
The average age of researchers funded by the NIH has risen by almost a decade to 53 years since the 1980s, but most Nobel laurates made their discovery younger than 40. After age 40, researchers increasingly cite older and more popular research, suggesting that they are further from the forefront of the field. As the age of researchers increases, they get further from the knowledge frontier but their chance of getting a highly cited paper in a highly cited journal keeps going up.
Academics are selected for their ability to write highly cited papers in prestigious journals. This is not unrelated to scientific advancement. A researcher needs similar abilities to do both. But as college, grad school, and top journals get more selective and the training time for academics gets longer, these metrics are being over-optimized for. Academic departments don’t have to settle for more lossy metrics of publishing ability. They can just choose candidates who already published something in a prestigious pre-doc. Journals and funding organizations don’t have to take risks on obscure researchers. A growing number of applications for a fixed number of spots means they can just fund and publish senior researchers who cite established work. This is good for these organizations because it decreases the error in what they are measured on: quantity and prestige of published work. But the line that perfectly minimizes the error in those metrics is the green squiggle we saw above.

It’s great at predicting who can add epicycles to Ptolemy’s model to improve its prediction of Mercury’s retrograde by 7% like their ancestors did. But it misses the crude Copernican model that can predict the orbits of planets no one has ever seen before. In our context, the long and rigorous training process allows only ‘productive’ researchers through. But it fails to extrapolate the fundamental trends that make great scientists.
Solutions
If the problem of overfitting can analogize from mathematics to academia, what can the mathematical solutions tell us?
One of the simplest and most useful strategies for preventing overfitting is early stopping. In the mathematical context, this means decreasing the error within the training set only as long as error continues to decrease in a separate validation set.
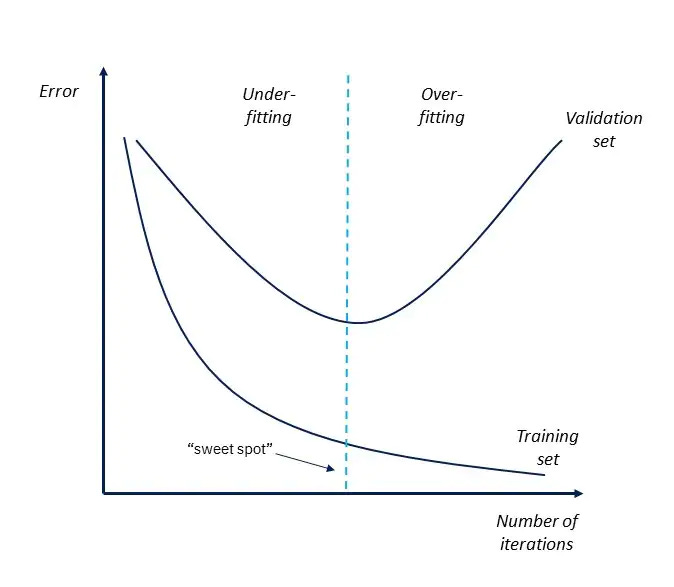
In the regression we started with separating the red and blue dots, the error on the training set is minimized by the green line. But if you test the green line on a different sample of red and blue dots from the same distribution it’s error will be huge, telling us that that model is on the right side of this graph. Low error in training is only associated with low error in validation up until a point.
In a real-world context we rarely have such a clean difference between training and validation and even less often the ability to switch between them at will. Still, the signs of overfitting are clear so we’d probably be better off if we required fewer credentials and less experience to do academic research.
This is part of the reason why Fast Grants, and Emergent Ventures work so well. There are obvious direct benefits from short applications and quick funding for urgent research. But it’s less obvious why Fast Grants seems to not trade off with the quality of their supported work, or even gain in quality, while putting much less time into the selection process. Early stopping provides an explanation. The error rate of fast grants was higher in the training set. It funded scientists who were less prestigious, less polished, and less published. But its error in the validation set: producing high impact research, was lower.
Another strategy is evaluating academics on a metric which is more closely related to the actual outcomes we want. This is the rationale behind CSPI’s forecasting tournament. They’re trying to hire for a fellowship position but
“Unlike a typical fellowship, you will not apply to this one by sending us letters of recommendation and a CV listing all of your publications and awards, and then relying on our subjective judgements about other people’s subjective judgments about your work. Rather, you will participate in a forecasting tournament on economics and social and political issues.”
They’re selecting candidates on a different training set than the traditional academic status ladder. This is currently more closely correlated with the validating outcomes, but if it became the main selection criteria for academic employment it would likely degrade as Campbell’s law takes hold. So when Richard Hanania says “Everyone knows expertise is fake,” what he means is that what we call expertise is performance on the training set: prestige, good grades, citations. Expertise is ‘fake’ because this performance is no longer positively correlated with performance on the validation set: creating new knowledge, making predictions, coherent opinions outside of a narrow field.
Unfortunately, credential inflation is an inefficient but attracting equilibrium in academia. Even if it is societally dysgenic, any individual benefits from extra credentials given what everyone else have. The non-profit, highly subsidized nature of the higher education market might have something to do with this. The existence of private companies is determined by their continued performance on the validation set of competitive forces. Not so with non-profits. Their validating outcomes are often more difficult to measure if anyone even cares to try, and they are weakly enforced. Charities succeed more based on the prestige of their donors than the impact of their donations. Universities benefit more from student’s performance on their own tests (“We accepted only the top 5% of applicants”), than on independent measures of quality. They are self-licking ice cream cones. But societally harmful and individually beneficial equilibria are difficult to break out of. I am not confident in academia’s will or ability to do so.
Overfitting is probably not academia’s biggest problem and fully fixing it would require an unrealistic scale of reform. Still, the overfitting perspective indicates that there are arbitrage opportunities in talent for private philanthropy and profit seeking. From an individual perspective, going through the over-fitting gauntlet is often still worth it, especially when seeking employment in organizations that suffer from this problem. When looking for undervalued talent, it is best to look for people who don’t fit the nitty gritty requirements of credentialism but still have the broad strokes characteristics of high research productivity.
Based
Happy to discuss at length but the term over fitting is too squishy. It is simply applied when someone thinks a process yields results they think are suboptimal.
Your example is showing an early stopping algorithm but I guarantee you people will still accuse of overfitting, rightfully so, even if you use early stopping. Often this occurs when yoi jave a poorly specified loss function or a badly chosen data set that learning the validation set still doesn't generalize.
I find this passage to be clarifiying for describing why overfitting is an underspecified, and unhelpful, term.
This came from Bob Carpenter on the Stan mailing list:
It’s not overfitting so much as model misspecification.
If your model is correct, “overfitting” is impossible. In its usual form, “overfitting” comes from using too weak of a prior distribution.
One might say that “weakness” of a prior distribution is not precisely defined. Then again, neither is “overfitting.” They’re the same thing.
P.S. In response to some discussion in comments: One way to define overfitting is when you have a complicated statistical procedure that gives worse predictions, on average, than a simpler procedure.
Or, since we’re all Bayesians here, we can rephrase: Overfitting is when you have a complicated model that gives worse predictions, on average, than a simpler model.
I’m assuming full Bayes here, not posterior modes or whatever.
Anyway, yes, overfitting can happen. And it happens when the larger model has too weak a prior. After all, the smaller model can be viewed as a version of the larger model, just with a very strong prior that restricts some parameters to be exactly zero